Innovation in Action: Document Detection - How Deep Learning Has Changed The Game
When we scan a document, our phone isn’t always perfectly paralleled with the page, leading to perspective distortion, where a rectangular document appears as a trapezoid shape. The goal of document detection is to accurately detect the edges and correct this distortion by “straightening” the image, so the result is a clean, rectangular scan—just like the flawless output you’d get from a flatbed scanner.
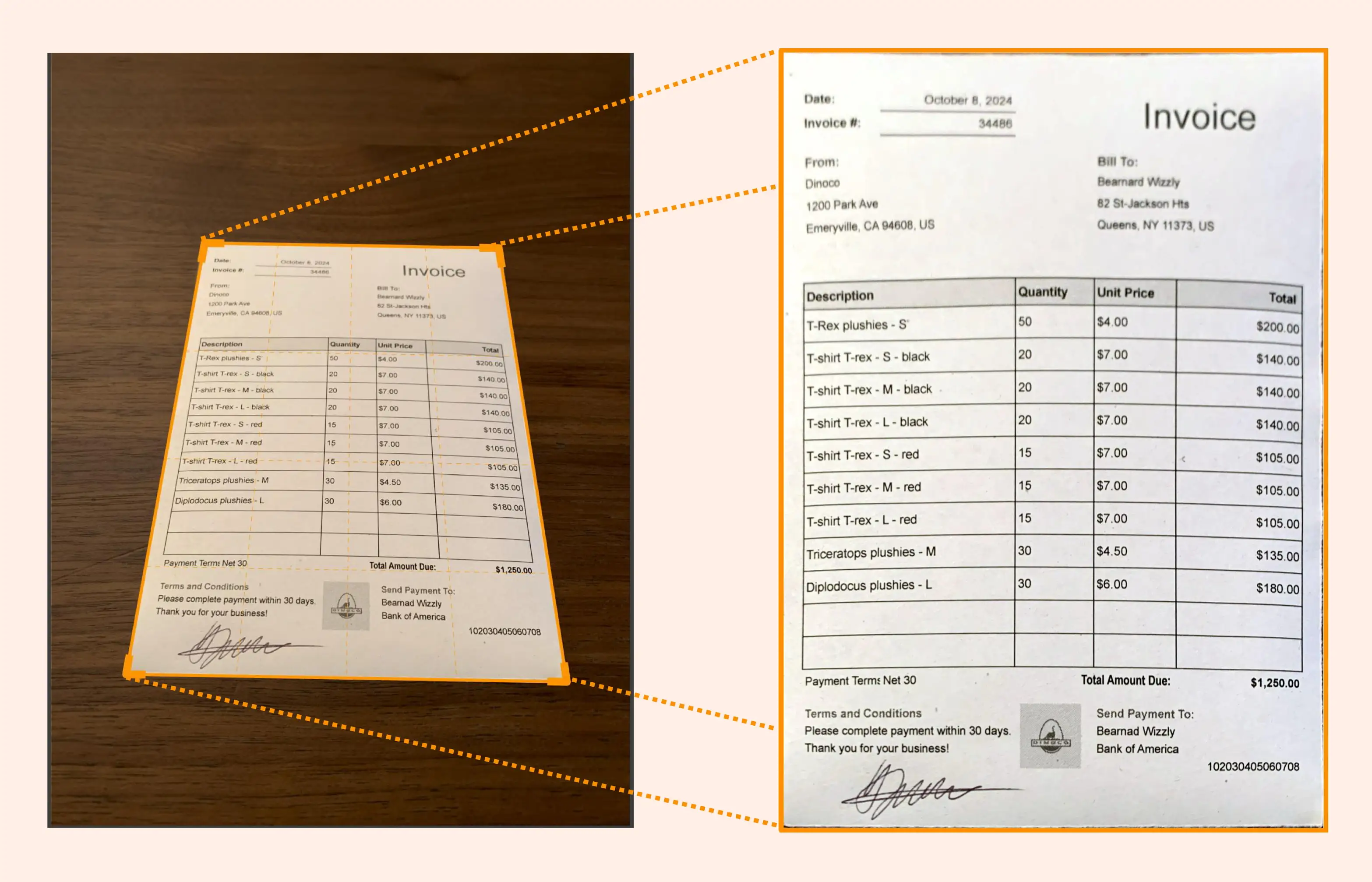
In our case, the first step in scanning a document with a smartphone is to detect four straight lines forming a quadrilateral that matches the edges of the document. This detection must be done in real-time to provide immediate visual feedback to the user so they can adjust the position of the smartphone or the document to obtain optimum results, as detection may not function properly when the phone is too tilted or rotated, or the document is too small or distant.
We conceived Genius Scan with this vision in mind from the outset. While our initial approach relied on traditional image processing techniques, we knew there was more to unlock. That’s when we decided to harness the power of Deep Learning. This shift didn’t just refine our document detection; it completely transformed it and drastically improved both accuracy and the overall user experience.
Traditional Image Processing
When we launched Genius Scan in 2010, it used conventional methods to detect document edges.
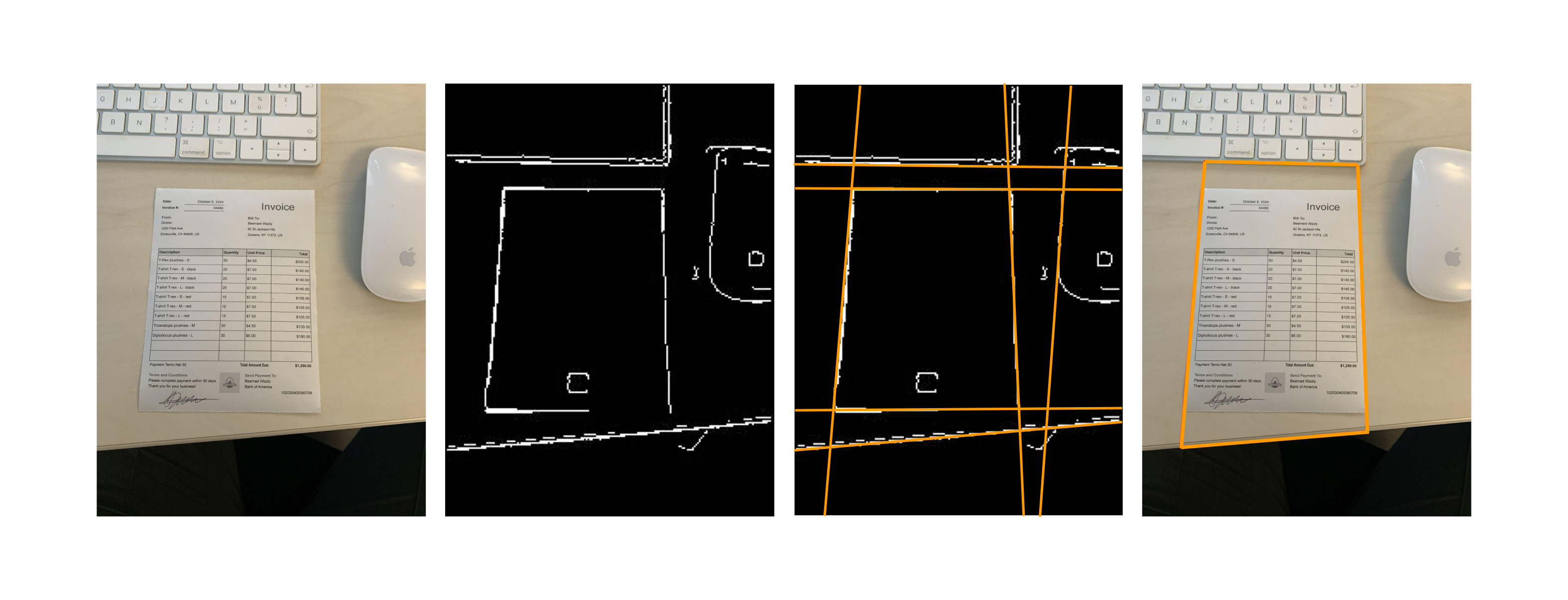
The process began with edge detection using the Canny filter, which highlights sharp transitions between light and dark areas of the image, allowing the system to identify potential document boundaries. From there, the Hough transform was used to detect straight lines in the image, helping to define the document’s edges. Finally, through a process called coherence selection, the algorithm chose the four most coherent lines that form a quadrangle which are used to correct perspective and crop the image.
At the time, making the application run smoothly on a wide range of smartphones, even the less powerful ones, was paramount. While effective for their time, these approaches constantly had to strike a balance between accuracy and speed to work on smartphones that were often limited in resources.
In addition, conventional image detection techniques could encounter difficulties processing cluttered or poorly contrasted backgrounds, limiting their effectiveness in certain situations. Future iterations of the house-built algorithm would have to address these different scenarios.
Throughout this decade, we constantly optimized Genius Scan’s algorithms to improve detection speed, accuracy, and the ability to separate documents from the background and better identify the straight lines that form their contours. However, despite these advances, in complex real use cases, the need to manually readjust some scanned documents remained for approximately 50% of the documents. We needed to find a newer and better way to detect documents.
Introducing Deep Learning
In 2020, Jonathan, a PhD expert in Artificial Intelligence, joined our team and invested several months in adopting Deep Learning. This technology would transform the approach to document detection, dramatically increasing the application’s accuracy and speed.
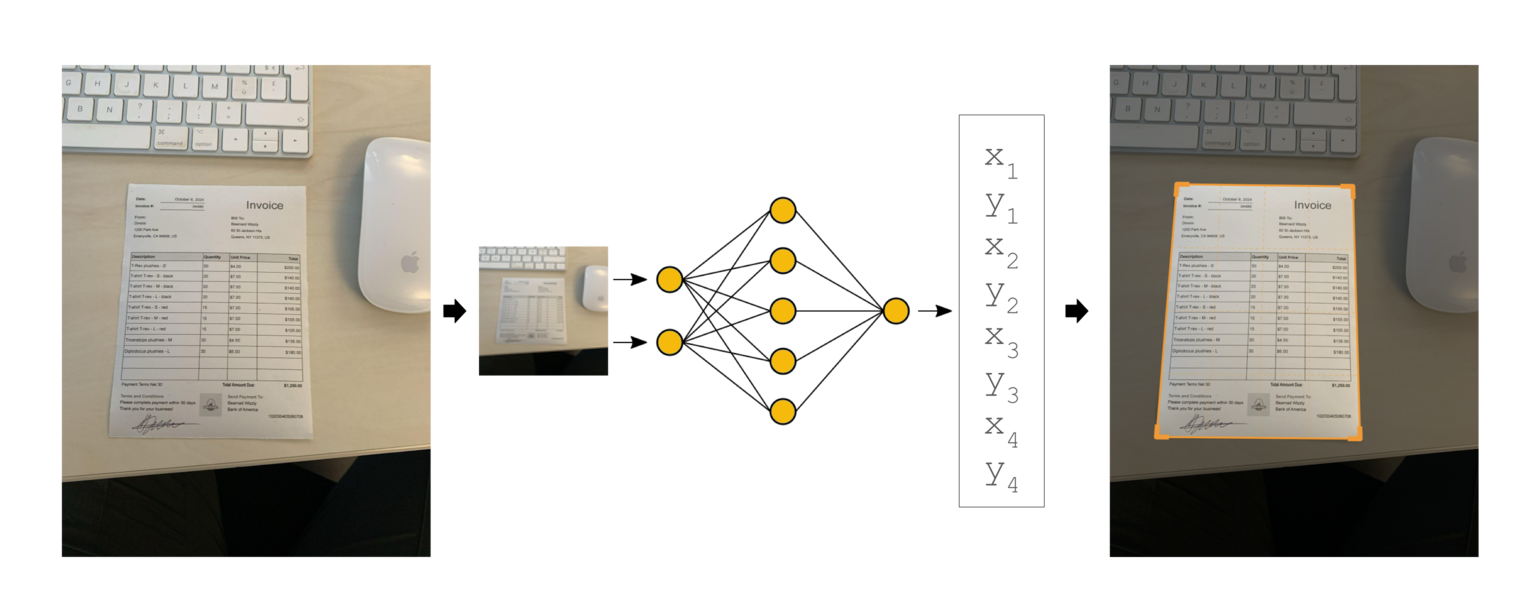
The core of this improvement is based on a neural network trained on a vast database of over a million images to identify document corners for real-world scanning scenarios accurately. Initially, our networks were pre-trained using the ImageNet image database and then further fine-tuned with Genius Scan-specific data to predict the coordinates of each corner of the document. This enables precise detection, even under challenging conditions such as low contrast or complex backgrounds.
Again, one of the major challenges in deploying Deep Learning on smartphones was to ensure that the algorithm would run smoothly, even on older devices. We had to strike a balance by optimizing the model’s complexity to keep it compatible with older devices so that the application could process at least 25 frames per second, ensuring a responsive and fluid user experience. To achieve this, we decided to use a specific neural architecture, MobileNet V2, and reduce images to very small resolutions (96x96 pixels).
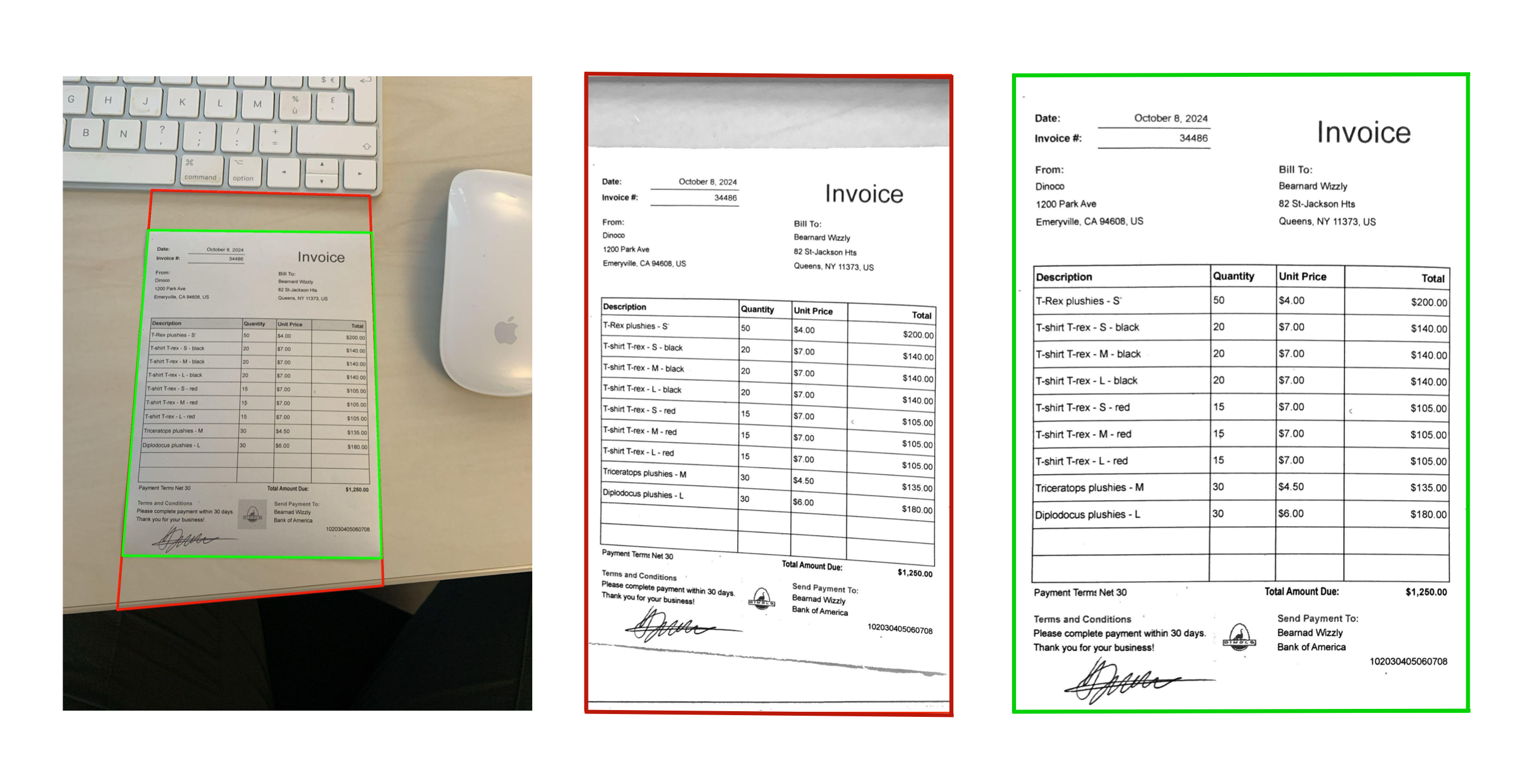
Although this neural network greatly improved document detection, it still required occasional manual adjustments. On the one hand, the network rarely made major mistakes like detecting unrelated objects (such as the edge of a table). Still, it often lacked precision, with detected edges being slightly off. On the other hand, traditional algorithms are more accurate but lack the robustness of the neural network. To balance these strengths and weaknesses, we decided to refine the Deep Learning approach with a conventional algorithm running consecutively, using the latter to refine the accuracy of the detected quadrilateral.
Correct detection rose from 51% to 75%
These impressive results considerably reduced the need for manual corrections and delivered a better user experience. Users were quick to notice the improvement, praising the application’s fluidity and ease of use. And we decided to continue down the Deep Learning road.
Iterative Improvements
In 2024, we wondered how to do even better than 75%, so we took matters into our own hands again to further perfect Genius Scan’s document detection techniques.
Thanks to the integration of artificial data simulating difficult conditions, such as paper piles, we were able to build up a new training base that was more representative of actual cases. This has enabled the algorithm to better deal with complex scenarios.
At the same time, we developed a second neural network to refine our Deep Learning approach and improve the final accuracy of the quadrilaterals detected.
The correct detection rate has risen from 75% to 85% compared to 2021, reducing the need for manual adjustments by 40%. Our unique document detection and processing approach sets Genius Scan apart from the competition, allowing us to deliver unparalleled reliability and innovation while staying true to our commitment to user simplicity and efficiency.
Outlook for the Future
Genius Scan’s innovation doesn’t stop there. We are already exploring new avenues to enhance its capabilities, including the ability to scan multiple pages simultaneously or better manage the detection of book pages. We remain committed to continuously improving Genius Scan’s technology, aiming to make scanning ever more efficient and accessible.